
Data Science 101 - Part 1
It is not uncommon for people to use different data science terms interchangeably, without really knowing that most of those terms have (some times slightly, most times completely) different meanings. In a series of posts I will try to define commonly used terms and give an overview of how I approach data science projects.
Data Science itself is a broadly used term, often used with many different meanings in mind. The main definition of Data Science is an interdisciplinary field that uses knowledge from Computer Science, Statistics, Information Sciences and application specific fields (among others) to extract insights and create models based on previously observed phenomena, all this while using scientific methods. The responsibilities of a data scientist varies a lot from company to company and even within the same company, on different teams or different projects.
Data Science is often used as a synonym for Data Mining, Data Analysis, Artificial Intelligence and Machine Learning. This is mostly because data scientist do use methods and knowledge from each of these fields while doing their work, however they are not exactly the same. Data Analysis consists of the methods and tools used to create a better understanding of a phenomena by considering recorded examples, and, from those, compute several measurements and create visualisations that allow the user to assess large quantities of information and data, which he/she would not be able to otherwise. These methods are regularly used by data scientists is many different situations such as: when the main objective is to extract insights from stored information; when starting a new project; and when assessing the quality and biases of machine learning models. Data Mining is field that focuses on how to combine. filter and transform existing information in order to generate new, clearer, information. These method are commonly used as part of Data Analysis projects.
Artificial Intelligence (AI) is the name given to the Computer Science field that studies and develops computer systems that are capable of performing tasks which require some kind of human intelligence. These programs or models are able to solve complex problems such as translating texts to different languages, identifying objects in a video and understanding requests made through voice commands. Among different Artificial Intelligence sub-fields, Machine Learning (ML) has taken a position of prominence. This sub-field focuses on the development of computer programs capable of making complex decisions by learning from past experience, that is, without explicit instructions. This is usually done through statistical and optimisation models and can be applied to many different problems, the only constraint being that data that is relevant to the underlying task needs to be available to train the model.
As is with Artificial Intelligence, Machine Learning also has many different sub-fields, like Statistical Learning Theory, Clustering and Artificial Neural Networks. Artificial Neural Networks (ANN, sometimes just called Neural Networks - NN) have existed for a long time but recently became famous due to the results achieved by Deep Learning methods. Artificial Neural Networks are models that are vaguely inspired on biological neural networks (brains!) and are usually composed by a set of computing units (neurons) which are connected to each other creating a network of units, from input to output. When these units are organised in a series of layers (and the number of layers start to grow), these models are known as Deep Learning (DL). Deep Learning methods create an hierarchy of concepts (each concept learned by a computing unit) by learning simpler concepts on units on the first layers (closer to the input), and combining those into more complex concepts the deeper into the network you go.
All these methods can be used in many different applications, such as Natural Language Processing, Computer Vision, Genomics and Financial Services. Since most of my experience is on Natural Language Processing and Computer Vision, I will focus on these two when describing applications and creating examples. Natural Language Processing (NLP) combines Linguistics and Computer Science with the aim to allow computers to interact with human languages. Applications explored by Natural Language Processing include Translation, Summarisation, Text Generation and Conversational Agents (A.K.A. chatbots). Computer Vision (CV) main goal is to enable computers to understand visual cues, typically in images or videos. That is, Computer Vision methods automates tasks usually performed by the human visual system. Some of the tasks these methods solve include Face Recognition, Object Detection, Motion Analysis and Image Restoration.
I created a Venn diagram to illustrate how some of these fields and sub-fields interact with each other. In this diagram, other application related fields could replace Natural Language Processing or Computer Vision. Several other subfields could also be included, however I did not want to make this over complicated.
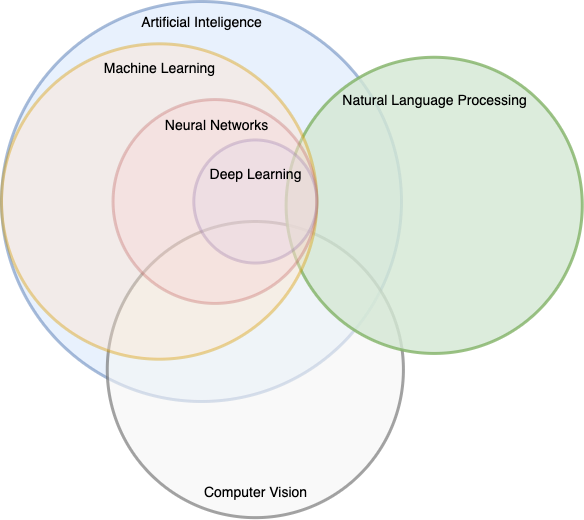 Venn diagram showing several data science related areas.
Venn diagram showing several data science related areas.
In this post, I tried to go over the areas within or related to data science by giving a simple definition of each and showing how they relate to each other. On my next post, I will go to focus on Machine Learning specifically by defining different learning approaches.

Leave a comment